KI-Souveränität ist ein Stack, kein Slogan
Vor wenigen Tagen hörte die abstrakte Debatte über KI-Souveränität auf, abstrakt zu sein. Als eine Export-Anordnung Anthropic dazu zwang, den Zugang zu Fable 5 und Mythos 5 für ausländische Staatsangehörige zu sperren, war die praktische Folge laut Anthropic, dass beide Modelle für alle Kunden abgeschaltet werden mussten, um der Anordnung zu entsprechen. Die Verfügbarkeit eines Modells war über Nacht zu einer Policy-Abhängigkeit geworden. Nicht wegen des Preises. Nicht wegen eines Vertragsstreits. Sondern weil sich eine Ebene des Stacks bewegt hat. Das ist die Souveränitätsdebatte, komprimiert in ein Wochenende.


Die meisten Reaktionen blieben auf derselben Flughöhe: Europa braucht souveräne KI, Unternehmen brauchen souveräne Cloud, Regierungen brauchen strategische Autonomie. Der Richtung stimme ich grundsätzlich vollkommen zu. Aber sobald man KI-Systeme tatsächlich baut oder kauft, wird die Frage deutlich konkreter.
Das Erste, was klar wird, ist: KI-Souveränität ist keine einzelne Tool-Entscheidung. Sie ist nicht die Wahl eines Modells, einer Cloud oder der Nationalität eines Anbieters. Sie ist eine Eigenschaft des gesamten Systems, verteilt über jede Ebene des Stacks und nur so stark wie das “schwächste” Glied in der Kette.
Wo genau braucht man Kontrolle?
Souveränität ist mehrschichtig
Der Reflex ist, Souveränität binär zu behandeln.
Souverän oder nicht. Cloud oder On-Prem. Offenes Modell oder geschlossenes Modell. Europäischer Anbieter oder US-Anbieter.
Die Realität ist leider unübersichtlicher.
Ein Unternehmen kann auf einer souveränen Cloud laufen und trotzdem von einer externen Modell-API abhängen. Es kann ein Open-Weight-Modell nutzen und sich trotzdem auf einen geschlossenen Orchestrierungs-Layer verlassen. Es kann die Daten besitzen und trotzdem den Kontext mieten, der den Daten Bedeutung gibt. Es kann die eigene Oberfläche bauen und trotzdem einen Anbieter darüber entscheiden lassen, wie Memory, Berechtigungen, Eskalationslogik und Workflow-Verhalten funktionieren.
Schon der Cloud-Layer zeigt, warum das schwierig ist.
Eine Frankfurt-Region oder eine EU-Datengrenze verbessert nur Teile des Bildes. Sie kann bei Datenhaltung, Latenz, Integration und Compliance helfen. Aber der Speicherort allein klärt nicht die Frage nach rechtlicher Exponierung, Anbieterkontrolle, Schlüsselhoheit, Auditierbarkeit oder operativer Resilienz.
Der CLOUD Act macht diese Spannung sichtbar. Ein Anbieter unter US-Jurisdiktion kann, je nach Anfrage und Umständen, verpflichtet sein, Daten in seiner Kontrolle herauszugeben, selbst wenn diese Daten außerhalb der USA gespeichert sind. Es gibt Schutzmechanismen, vertragliche Absicherungen und technische Maßnahmen wie kundeneigene Schlüssel. Die ehrliche Schlussfolgerung ist also nicht „Ihre Daten sind exponiert".
Die ehrliche Schlussfolgerung ist, dass Souveränität von Architektur, Vertrag, Verschlüsselung, Governance und operativer Kontrolle gemeinsam abhängt.
Und es lohnt sich, genau zu sein, was „Daten" hier heißt, denn man denkt schnell nur an Datensätze und Dateien. Der operative Kontext, den ein agentisches System ansammelt — sein Memory, seine Korrekturen, Definitionen, gelernten Ausnahmen. Alles ebenfalls Daten. Die Jurisdiktions- und Kontrollfragen, die für die Datenebene gelten, hören also nicht dort auf; sie reichen bis zu genau der Ebene, die das Verhalten des Systems definiert. Genau deshalb lassen sich die Layer nicht als getrennte Silos behandeln.
Das ist der Punkt: KI-Souveränität ist kein Etikett, das man einem System anheftet. Sie ist eine Kontroll-Landkarte.
Der Stack hat Kontroll-Layer
Für agentische KI würde ich mindestens sechs Layer unterscheiden.
1. Infrastruktur ist die sichtbare Basis:
Compute, Storage, Deployment, Cloud-Region und Betriebsumgebung.
2. Model Serving ist der nächste Layer:
welche Modelle genutzt werden, wo sie laufen, wie sie geroutet werden und ob sie sich ersetzen, selbst hosten oder mit Fallbacks kombinieren lassen.
3. Agent Runtime ist, wo Verhalten zu entstehen beginnt:
Planung, Memory, Tool-Nutzung, Ausführungslogik und Workflow-Verhalten.
4. Daten und Wissen ist der Layer, den ich für am meisten unterschätzt halte.
Er umfasst die klassischen Grundlagen: Warehouses, Lakehouses, Semantic Layer, maßgebliche Quellen, Lineage, Qualität und Zugriffskontrolle. Aber agentische KI legt noch etwas obendrauf: Definitionen, Ausnahmen, Korrekturen, wiederverwendbare Skills, Berechtigungen, Workflow-Muster, Confidence-Schwellen und institutionelles Gedächtnis.
5. Governance entscheidet, wer freigeben, ändern, prüfen, überwachen, versionieren und erklären darf, was das System tut.
6. Interface ist der Ort an dem Nutzer Gewohnheiten, Vertrauen, und Abkürzungen aufbauen.
Jeder Layer kann intern kontrolliert, mit einem Anbieter geteilt oder faktisch von jemand anderem kontrolliert werden.
Deshalb ist souveräne Cloud nicht dasselbe wie souveräne KI. Souveräne Cloud verbessert das untere Ende des Stacks. Über die Layer darüber sagt sie viel weniger aus: Runtime, Memory, Governance, Kontext und Nutzerabhängigkeit.
Die eigentliche Abhängigkeit sitzt nicht immer dort, wo es am sichtbarsten ist. Sie sitzt oft dort, wo Verhalten definiert wird.
Der Schwerpunkt verschiebt sich nach oben
Klassischer Vendor-Lock-in war leichter zu erkennen. Daten waren schwer zu bewegen. Verträge waren restriktiv. Oberflächen waren proprietär. Migration war teuer.
Das alles zählt immer noch.
Aber agentische KI verschiebt den Schwerpunkt nach oben. Sobald Systeme planen, Tools aufrufen, Datensätze aktualisieren, Workflows auslösen und Empfehlungen geben, werden die kritischen Layer zu Runtime, Governance und operativem Kontext.
Der Modell-Layer ist der, vor dem gerade alle nervös sind, aus gutem Grund. Aber die praktische Antwort auf einen volatilen Modell-Layer ist nicht, alles um ein Modell herum zu bauen. Es gilt den Modell-Layer ersetzbarer zu machen, als viele aktuelle Architekturen es zulassen, auch wenn ein Wechsel nie kostenlos wird. Zwischen Modellen zu wechseln kostet weiterhin echtes Re-Tuning von Prompts, Tools und Evaluationen; der Punkt ist, diese Kosten im austauschbaren Layer zu halten, statt sie in den Layern darüber verhärten zu lassen.
Der Markt bewegte sich aus Kostengründen ohnehin schon dorthin.
Tokenomics zeigt in dieselbe Richtung
Nicht jede Aufgabe braucht ein Frontier-Modell.
Ein Ticket klassifizieren, einen Datensatz taggen, ein Feld extrahieren, ein Dokument zusammenfassen oder eine einfache Regel prüfen — das können oft kleinere, günstigere, spezialisierte oder offene Modelle übernehmen. Schwieriges Reasoning kann bei stärkeren Modellen bleiben. Fallback-Ketten können Qualitätsschwellen abfangen.
Das ist gutes Engineering. Nach den jüngsten Zugangsbeschränkungen ist es auch gutes Risikomanagement. Aber sobald der Modell-Layer dynamisch wird, muss ein anderer Layer stabil bleiben.
Jedes Modell braucht denselben operativen Kontext. Es muss verstehen, was eine Kennzahl bedeutet, welche Quelle maßgeblich ist, welche Ausnahme zählt, wer welche Berechtigung hat, wann eskaliert werden muss und welches Confidence-Niveau ausreicht. Ohne einen gemeinsamen, modellunabhängigen Kontext-Layer schafft eine Multi-Modell-Architektur keine Resilienz. Sie schafft verteilte Verwirrung.
Ein Modell liest „Kunde" auf die eine Art. Ein anderes liest ihn anders. Ein Workflow vertraut einer Quelle, die ein anderer überschreibt. Ein Agent eskaliert eine Anomalie, die ein anderer ignoriert. Je dynamischer der Modell-Layer wird, desto sorgfältiger müssen Unternehmen den Kontext-Layer behandeln.
Wo sich der Wert ansammelt
In den meisten Enterprise-Setups trainiert das Unternehmen nicht direkt das Foundation Model. Das bleibt das Modell des Anbieters.
Was das Unternehmen formt, ist der operative Layer um das Modell herum: Prompts, Memory, Tools, Routing-Logik, Agent Skills, Workflow-Muster, Evaluationen, Korrekturen und Geschäftsregeln. Dort entsteht das eigentliche Gedächtnis.
Jeder Prompt, der funktioniert, jede Korrektur, jede abgelehnte Empfehlung, jede Workflow-Anpassung, jede Eskalation und jede Ausnahme bringt dem System etwas darüber bei, wie die Organisation tatsächlich arbeitet.
Stellen Sie sich einen Finance-Agenten vor, der das monatliche Reporting unterstützt.
Anfangs erklärt er nur Abweichungen: Umsatz hat sich hier verschoben, Kosten sind dort gestiegen, diese Kostenstelle liegt über Plan. Nützlich, aber noch generisch.
Dann beginnt das Finance-Team, ihn zu korrigieren. Manche Kostenstellen sind Sonderfälle. Manche Lieferanten verzerren die Zahlen. Manche Verschiebungen sind zum Quartalsende normal. Ein Quellsystem hat sich vor drei Monaten geändert. Eine Anomalie zählt, eine andere nicht. Eine Erklärung funktioniert beim Management, eine andere stiftet Verwirrung.
Nach sechs Monaten liegt der Wert dieses Agenten nicht mehr nur im Modell oder in der Datenanbindung. Der Wert liegt im angesammelten Verständnis, wie dieses Unternehmen seine eigenen Zahlen liest. Jetzt versuchen Sie, die Plattform zu wechseln. Die Daten wandern. Die Dashboards werden neu gebaut. Das Modell kann sich ändern.
Aber die sechs Monate an Korrekturen, Ausnahmen und Bewertungsentscheidungen kommen womöglich nicht in einer nutzbaren Form heraus. Datensätze können exportiert werden.
Das Verständnis nicht ohne Weiteres, es sei denn, es wurde entsprechend gebaut.
Denn dieses Verständnis ist ebenfalls Daten: Korrekturen, Ausnahmen, Definitionen, Confidence-Schwellen. Der Grund, warum es sich meist nicht bewegen lässt, ist nicht, dass es von Natur aus unstrukturiert wäre, sondern dass die meisten Plattformen es nie als etwas Portierbares erfassen. Es lebt als vergrabene Prompts und implizite Einstellungen statt als eigener, prüfbarer, exportierbarer Kontext. Das heißt: Es ist eine Designentscheidung, kein Naturgesetz — und genau das, was es zu Daten macht, macht es möglich, es zu behalten.
Und in einem agentischen System ist dieses Verständnis keine passive Dokumentation mehr. Es beeinflusst zunehmend, was das System empfiehlt, eskaliert, priorisiert oder als Nächstes tut.
Liegt dieser Layer in einer geschlossenen Plattform, besitzt das Unternehmen vielleicht die Daten, mietet aber die Intelligenz, die gelernt hat, sie zu nutzen.
Interessanterweise ist das längst keine Außenseiterposition mehr. Auf der Microsoft Build im Juni 2026 plädierte Satya Nadella dafür, dass die Priorität ein Frontier-Ecosystem sein müsse, nicht nur ein Frontier-Modell — eines, in dem, in seinen Worten, jede Organisation
„own the learning loop that encodes its institutional knowledge".
Wenn der CEO eines der größten Modellanbieter davor warnt, dass Unternehmen ihr Wissen an eine Handvoll Modelle abtreten, ist die Richtung deutlich genug.
Dem Ziel stimme ich zu. Aber ich würde den Akzent an eine unbequemere Stelle setzen. Einem Ökosystem tritt man bei; es ist für sich genommen kein Eigentum. Die Frage ist nicht nur, in welchem Ökosystem man baut, sondern welche Layer einem bleiben, wenn dieses Ökosystem seine Bedingungen, seine Preise oder seinen Zugang ändert. Den Learning Loop zu besitzen ist kein Feature, das eine Plattform gewährt. Es ist eine architektonische Entscheidung, die man auf Ebene des Stacks treffen und verteidigen muss.
Die Kontroll-Matrix
Hier wird die Souveränitätsdebatte zur Architektur.
Die relevante Frage ist nicht, ob man Anbieter komplett vermeiden sollte. Das ist unrealistisch und oft unklug. Die eigentliche Frage ist, welche Layer ersetzbare Ausführungskapazität sind und welche Layer das Verhalten definieren.
Modelle werden ersetzbarer, wie sowohl der Kostendruck als auch die jüngsten Zugangsereignisse zeigen. Infrastruktur lässt sich oft ändern. Oberflächen lassen sich neu bauen. Aber Governance, Memory, Kontext und fachliche Bedeutung sind sehr viel schwerer zu rekonstruieren, sobald sie sich im Ausführungs-Layer eines anderen gebildet haben.
Bevor agentische Systeme also tief eingebettet werden, sollten Unternehmen den Stack Layer für Layer kartieren.
Wer kontrolliert ihn? Wo sammelt sich operatives Wissen an? Lässt es sich prüfen, exportieren und verifizieren? Genau dafür ist die Matrix unten da.
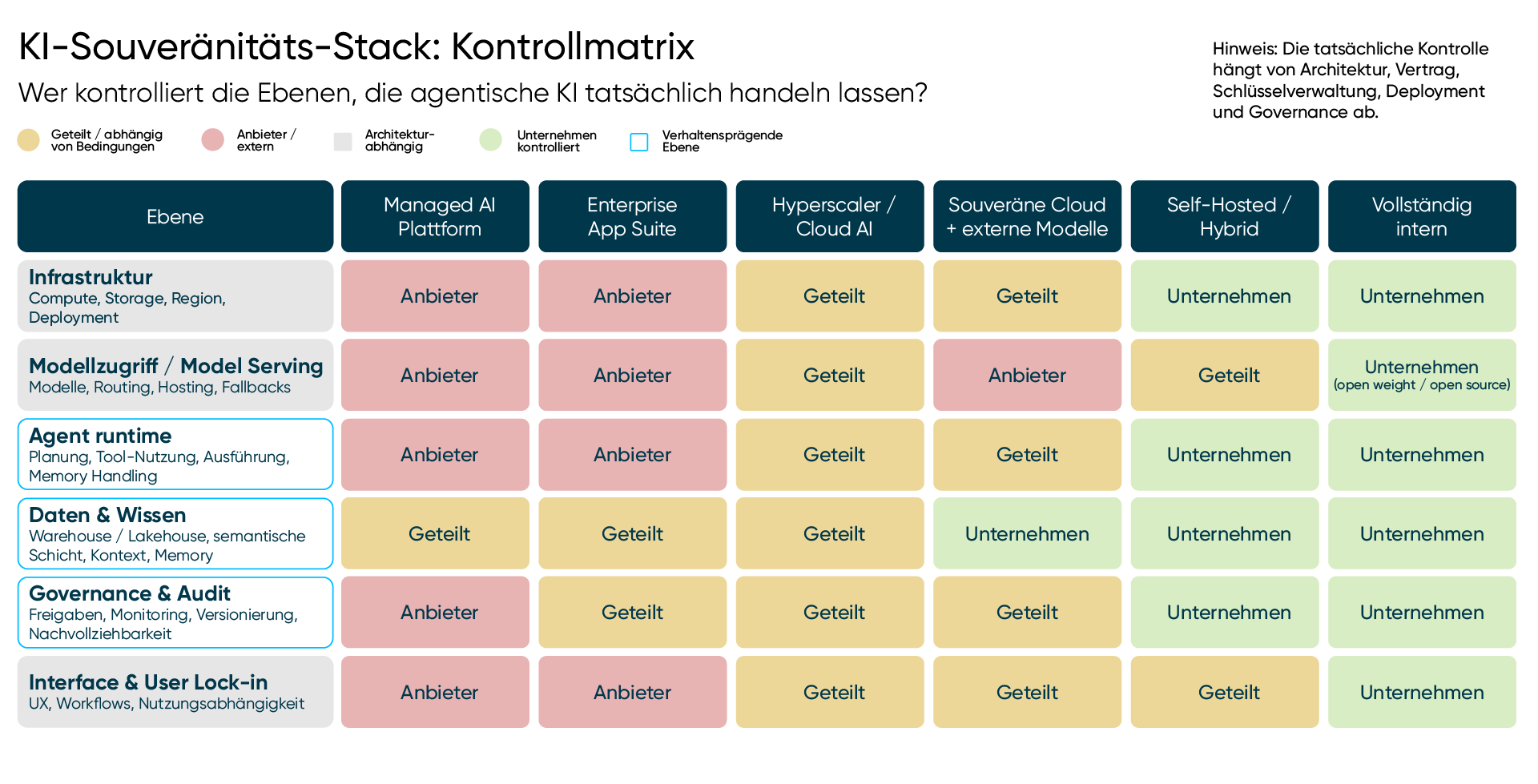
Info:
Lesen Sie die Matrix von unten nach oben. Infrastruktur-Souveränität ist hilfreich. Agentische Souveränität entsteht jedoch in den Ebenen, die Verhalten bestimmen: Runtime, Kontext, Wissen, Governance. Nutzen Sie die Matrix als Diskussionsgrundlage, nicht als rechtliche Bewertung.
Der Sinn dieser Matrix ist nicht, eine Architektur für richtig zu erklären. Er ist, sichtbar zu machen, welche Sie tatsächlich betreiben und ob die Layer, die Sie mieten, die Layer sind, die Sie sich zu mieten leisten können.
Die Regulierung bewegt sich in dieselbe Richtung
Ich würde das noch nicht als gelöstes Feld behandeln. Es gibt keinen etablierten Standard dafür, wie die oberen Layer agentischer Systeme plattformübergreifend besessen, gesteuert, exportiert und verifiziert werden sollten. Die regulatorische Seite bewegt sich in dieselbe Richtung.
Der EU AI Act drängt den Markt in Richtung Dokumentation, Auditierbarkeit und Post-Market-Monitoring für Hochrisiko-KI-Systeme, während die praktische Durchsetzung und Audit-Praxis noch im Entstehen ist.
Im Finanzsektor ist die Wechselbarkeitsfrage bereits konkreter. Unter DORA müssen Unternehmen ihr IKT-Drittparteienrisiko steuern, Register über IKT-Vereinbarungen führen, Konzentrationsrisiken bewerten und Exit-Strategien sowie Übergangspläne für IKT-Dienste vorhalten, die kritische oder wichtige Funktionen unterstützen.
Das ist für einige unserer Kunden relevant. Viele agieren in regulierten Umfeldern, wo die Fähigkeit, operativen Kontext zu prüfen, zu erklären und zu bewegen, der Unterschied ist zwischen einem System, das man im Audit verteidigen kann, und einem, das man nicht verteidigen kann. Genau hier sitzt ein Großteil der aufkommenden Herausforderungen.
Wir bauen Kontroll-Layer bereits in verschiedenen Ausprägungen, intern und mit Kunden: Kontext, Governance und operatives Gedächtnis bleiben im Eigentum, prüfbar und portabel, statt im Ausführungs-Layer eines anderen gefangen zu sein.
KI braucht mehr als ein gutes Modell
Erfolgreiche KI basiert auf belastbaren Daten, klarer Governance und einer tragfähigen Architektur. Finden Sie heraus, wo Ihr Unternehmen heute steht.
KI-Grundlage prüfen lassenVon Technologie-Souveränität zu Entscheidungs-Souveränität
Am meisten zählt das in Analytics, wo Agenten aufhören zu beobachten und anfangen mitzuwirken. Klassische BI hatte einen menschlichen Puffer. Ein Dashboard informierte jemanden, ein Report unterstützte ein Meeting, und die Entscheidung fiel an anderer Stelle.
Agentic Analytics lässt diesen Puffer zusammenfallen. Das System erklärt Veränderungen, identifiziert Anomalien, empfiehlt Maßnahmen, aktualisiert Datensätze, öffnet Tickets, entwirft Narrative und eskaliert Risiken. Ab diesem Punkt wird schwacher oder anbietergebundener Kontext zum operativen Risiko.
Eine falsch gelesene Kennzahl wird zur falschen Empfehlung. Eine falsch vertraute Quelle wird zur falschen Eskalation. Ungesteuerte Korrekturen werden zu reproduziertem Bias.
Die Frage verschiebt sich von Infrastruktur zu Entscheidungskontrolle.
Kann die Organisation noch den Anbieter wechseln? Kann sie nachvollziehen, warum eine Empfehlung zustande kam? Kann sie nachweisen, welche Quelle, Regel oder Definition eine Antwort geprägt hat? Kann sie einen automatisierten Prozess stoppen, überschreiben oder umleiten? Kann sie ihr operatives Gedächtnis transportieren?
Das ist die Verschiebung von Technologie-Souveränität zu Entscheidungs-Souveränität.
Der Provenienz-Layer
Dasselbe Muster zeigt sich in der digitalen Provenienz, nur in einer anderen Domäne.
Wenn Herkunft, Rechte und Kontext vollständig von einer geschlossenen Plattform abhängen, wird Vertrauen plattformabhängig.
Anderes Problem, aber dieselbe architektonische Frage: Kann der Nachweis mitwandern?
Lässt sich der Kontext über das System hinaus verifizieren, das ihn gerade anzeigt? Übersteht der Datensatz einen Plattformwechsel? Kann eine Institution, ein Unternehmen oder ein Nutzer noch nachvollziehen, woher etwas kam, was sich geändert hat, wer es freigegeben hat und warum man ihm vertrauen sollte?
Deshalb sehe ich Provenienz nicht nur als Thema der Medienintegrität. Sie ist Teil der breiteren Kontroll-Infrastruktur, die KI-Systeme brauchen werden.
Provenienz von Inhalten. Provenienz von Wissen. Provenienz von Entscheidungen.
Die Domänen sind verschieden, aber die zugrunde liegende Anforderung ist ähnlich: Vertrauen sollte nicht davon abhängen, dass eine geschlossene Umgebung weiter existiert, kooperiert oder zugänglich bleibt.
Was dieser Moment wirklich gelehrt hat
KI-Souveränität ist wichtig. Aber ich würde sie nicht auf Cloud-Region, Anbieter-Nationalität oder Modellwahl reduzieren. Sie ist keine einzelne Tool-Entscheidung sie ist ein Zusammenspiel des gesamten Stacks.
Der Modell-Layer hat gerade bewiesen, dass er sich bewegen kann.
Die praktische Antwort ist, sicherzustellen, dass die Layer, die sich bewegen, ersetzbar sind und dass die Layer, die das organisationale Gedächtnis tragen, nicht mit ihnen gefangen sind.
Die erste Generation der Enterprise-KI-Einführung fragte:
Welches Modell sollten wir nutzen?
Die nächste Generation wird fragen:
Welche Layer kontrollieren wir?
Konkreter:
Wo lebt unser operatives Gedächtnis, wer kann es verifizieren, und können wir es mitnehmen?
Modelle können sich ändern. Anbieter können sich ändern. Preise und Zugang können sich ändern, manchmal über ein einziges Wochenende.
Aber der Kontext, der KI innerhalb einer Organisation nützlich macht, sollte nicht verschwinden, wenn sich eine Ebene des Stacks bewegt. Unternehmen, die das verstehen, werden KI nicht nur mieten. Sie werden die Intelligenz besitzen, die sie aufbauen.
Das ist der rote Faden, der beide Themen verbindet, an denen ich arbeite: gesteuerter, eigener Kontext bei inics und überprüfbare Provenienz bei puit.is. Content, Context, Confidence — über den ganzen Stack.
KI Souveränität beginnt im Stack
Wir helfen Ihnen, KI Architekturen so aufzubauen, dass Kontext, Governance und operatives Wissen unter Ihrer Kontrolle bleiben.
Architektur Sparring vereinbarenThomas Howert
Co-Founder & Senior Advisor für BI-, Datenprojekte und Technologieentscheidungen
Weitere Artikel entdecken

AI Use Case Inventar und Governance - Portfolio, Rollen, Pflichten
Teil 3/3 schließt die Reihe mit der Frage, die in der Praxis oft als Erstes beantwortet werden muss:

Vom Erkenntnisrisiko zum Handlungsrisiko: Wenn Analytics zur Handlung wird, wird Governance zur Ausführungslogik
In klassischer BI war schwache Governance ein Reporting-Problem. In Agentic Analytics wird sie zu einem Ausführungsproblem. Diese Verschiebung allein bestimmt, wo Governance neu ansetzen muss – und wo Organisationen beginnen sollten, bevor sie KI skalieren.

Der Analytics Agent arbeitet bereits in Ihrem Unternehmen
Das Problem: Der größte Teil dieses Wissens steckt noch immer in den Köpfen einzelner Menschen. In vielen Unternehmen ist das, was einem Analytics Agent am nächsten kommt, noch immer eine Person. Der Analyst, der weiß, welchem Dashboard die Fachbereiche tatsächlich vertrauen. Die Controllerin, die sich daran erinnert, warum eine bestimmte Margenlogik gefährlich ist. Der BI-Berater, der erlebt hat, dass dieselbe einfache Kennzahl in drei Quellsystemen drei unterschiedliche Bedeutungen haben kann. Die Data Engineerin, die weiß, welche Tabelle existiert und warum sie für die konkrete Frage trotzdem nicht verwendet werden sollte.