AI Sovereignty Is a Stack, Not a Slogan
A few days ago, the abstract debate about AI sovereignty stopped being abstract. When an export-control directive required Anthropic to suspend access to Fable 5 and Mythos 5 for foreign nationals, Anthropic said the practical effect was that it had to disable both models for all customers to comply. Model availability had become a policy dependency overnight. Not because of price. Not because of a contract dispute. Because one layer of the stack moved. That is the sovereignty debate, compressed into one weekend.


Most reactions stayed at the same altitude: Europe needs sovereign AI, companies need sovereign cloud, governments need strategic autonomy. I agree with the direction. But once you are actually building or buying AI systems, the question becomes much more practical.
And the first thing that becomes clear is this: AI sovereignty is not a single tool decision. It is not the choice of one model, one cloud, or one provider's nationality. It is a property of the whole system — distributed across every layer of the stack, and only as strong as the weakest one you do not control.
Where exactly do you need control?
Sovereignty is layered
The instinct is to treat sovereignty as a switch.
Sovereign or not. Cloud or on-prem. Open model or closed model. European provider or US provider. Reality is messier.
A company can run on a sovereign cloud and still depend on an external model API. It can use an open-weight model and still rely on a closed orchestration layer. It can own the data and still rent the context that gives the data meaning. It can build its own interface and still let a vendor define memory, permissions, escalation logic, and workflow behaviour.
The cloud layer already shows why this is difficult.
A Frankfurt region or an EU data boundary improves parts of the picture. It can help with data residency, latency, integration and compliance posture. But data location alone does not settle the question of legal exposure, provider control, key custody, auditability or operational resilience.
The CLOUD Act makes that tension visible. A provider under US jurisdiction may, depending on the request and circumstances, be required to produce data in its control even if that data is stored outside the United States. There are safeguards, challenge mechanisms, contractual protections and technical mitigations such as customer-held keys. So the honest conclusion is not "your data is exposed."
The honest conclusion is that sovereignty depends on architecture, contract, encryption, governance and operational control together.
And it is worth being precise about what "data" means here, because it is easy to picture only records and files. The operating context an agentic system accumulates — its memory, corrections, definitions, learned exceptions — is data too. So whatever jurisdictional and control questions apply to the data layer do not stop there; they reach the very layer that defines how the system behaves. That is exactly why the layers cannot be treated as separate silos.
That is why the layers cannot be read in isolation.
Even a setup that sounds very sovereign at first — for example an open-weight model running in a European region — still raises further questions. Who controls the keys? Who operates the environment? Which jurisdiction reaches the provider? What can actually be accessed? What can be audited? What can move?
None of this has a universal answer. It depends on how the system is built. That is the point. AI sovereignty is not a label you attach to a system. It is a control map.
The stack has control layers
For agentic AI, I would at least separate six layers.
1. Infrastructure is the visible base:
compute, storage, deployment, cloud region and operating environment.
2. Model serving is the next layer:
which models are used, where they run, how they are routed, and whether they can be replaced, self-hosted or combined with fallbacks.
3. Agent runtime is where behaviour starts to emerge:
planning, memory, tool use, execution logic and workflow behaviour.
4. Data and knowledge is the layer I think is most underestimated.
This includes the classic foundations — warehouses, lakehouses, semantic layers, authoritative sources, lineage, quality and access control — but agentic AI adds something on top: definitions, exceptions, corrections, reusable skills, permissions, workflow patterns, confidence thresholds and institutional memory.
5. Governance
decides who can approve, change, inspect, monitor, version and explain what the system does.
6. Interface
is where users build habits, trust, shortcuts and switching costs.
Each layer can be controlled internally, shared with a vendor, or effectively controlled by someone else.
That is why sovereign cloud is not the same as sovereign AI. Sovereign cloud improves the bottom of the stack. It says much less about the layers above it: runtime, memory, governance, context and user dependency.
The real dependency does not always sit where the invoice is most visible. It often sits where behaviour is defined.
The centre of gravity is moving upward
Classic vendor lock-in was easier to recognise. Data was hard to move. Contracts were restrictive. Interfaces were proprietary. Migration was expensive.
All of that still matters. But agentic AI moves the centre of gravity upward. Once systems plan, call tools, update records, trigger workflows and make recommendations, the critical layers become runtime, governance and operating context.
The model layer is the one everyone is anxious about right now, for good reason. But the practical response to a volatile model layer is not to build everything around one model. It is to make the model layer more replaceable than many current architectures allow — replaceable as execution capacity, even if switching never becomes free. Moving between models still costs real re-tuning of prompts, tools and evaluations; the point is to keep that cost in the swappable layer instead of letting it harden into the layers above.
The market was already moving there for cost reasons.
Tokenomics points in the same direction
Not every task needs a frontier model.
Classifying a ticket, tagging a record, extracting a field, summarising a document or checking a simple rule can often be handled by smaller, cheaper, specialised or open models. Hard reasoning may stay with stronger models. Fallback chains can handle quality thresholds.
That is good engineering. After recent access restrictions, it is also good risk management. But once the model layer becomes dynamic, another layer has to stay stable.
Every model still needs the same operating context. It needs to understand what a metric means, which source is authoritative, which exception matters, who has permission, when escalation is required and what confidence level is enough. Without a shared, model-independent context layer, multi-model architecture does not create resilience. It creates distributed confusion.
One model reads "customer" one way. Another reads it differently. One workflow trusts a source another overrides. One agent escalates an anomaly another ignores. The more dynamic the model layer becomes, the more carefully companies need to treat the context layer.
Where the value accumulates
In most enterprise setups, the company is not training the foundation model directly. That remains the vendor's model.
What the company is shaping is the operating layer around the model: prompts, memory, tools, routing logic, agent skills, workflow patterns, evaluations, corrections and business rules.
That is where the real memory forms.
Every prompt that works, every correction, every rejected recommendation, every workflow adjustment, every escalation and every exception teaches the system something about how the organisation actually operates. Imagine a finance agent supporting monthly reporting.
At first it explains deviations: revenue moved here, costs rose there, this cost centre is above plan. Useful, but still generic. Then the finance team starts correcting it. Some cost centres are special cases. Some suppliers distort the numbers. Some shifts are normal at quarter end. A source system changed three months ago. One anomaly matters, another does not. One explanation works for management, another creates confusion.
After six months, the value of that agent is no longer only the model or the data connection. The value is the accumulated understanding of how this company reads its own numbers. Now try to switch platforms. The data moves. The dashboards rebuild. The model can change. But the six months of corrections, exceptions and judgement calls may not come out in a usable form.
You can export the records. The understanding does not come with them — unless you built it to.
Because that understanding is also data: corrections, exceptions, definitions, confidence thresholds. The reason it usually cannot be moved is not that it is unstructured by nature, but that most platforms never capture it as something portable. It lives as buried prompts and implicit settings instead of owned, inspectable, exportable context. Which means this is a design choice, not a law of physics — and the same fact that makes it data is what makes it possible to keep it yours.
And in an agentic system, that understanding is no longer passive documentation. It increasingly shapes what the system recommends, escalates, prioritises or does next.
If that layer lives inside a closed platform, the company may own the data while renting the intelligence that learned how to use it.
Interestingly, this is no longer a fringe view. At Microsoft Build in June 2026, Satya Nadella argued that the priority should be a frontier ecosystem, not just a frontier model — one where, in his words, every organisation can
"own the learning loop that encodes its institutional knowledge."
When the CEO of one of the largest model providers warns against companies ceding their knowledge to a handful of models, the direction of travel is clear enough.
I agree with the goal. But I would put the emphasis somewhere more uncomfortable. An ecosystem is something you join; it is not, by itself, a title of ownership. The question is not only which ecosystem you build in, but which layers stay yours when that ecosystem changes its terms, its prices, or its access. Owning the learning loop is not a feature a platform grants you. It is an architectural choice you have to make — and defend — at the level of the stack.
The control matrix
This is where the sovereignty debate becomes architecture.
The relevant question is not whether to avoid vendors completely. That is unrealistic and often unwise. The real question is which layers are replaceable execution capacity, and which layers define behaviour.
Models are becoming more replaceable as both cost pressure and recent access events show. Infrastructure can often be changed. Interfaces can be rebuilt. But governance, memory, context and business meaning are much harder to reconstruct once they have formed inside someone else's execution layer.
So before agentic systems become deeply embedded, companies should map the stack layer by layer.
Who controls it? Where does operating knowledge accumulate? Can it be inspected, exported and verified?
That is what the matrix below is for.
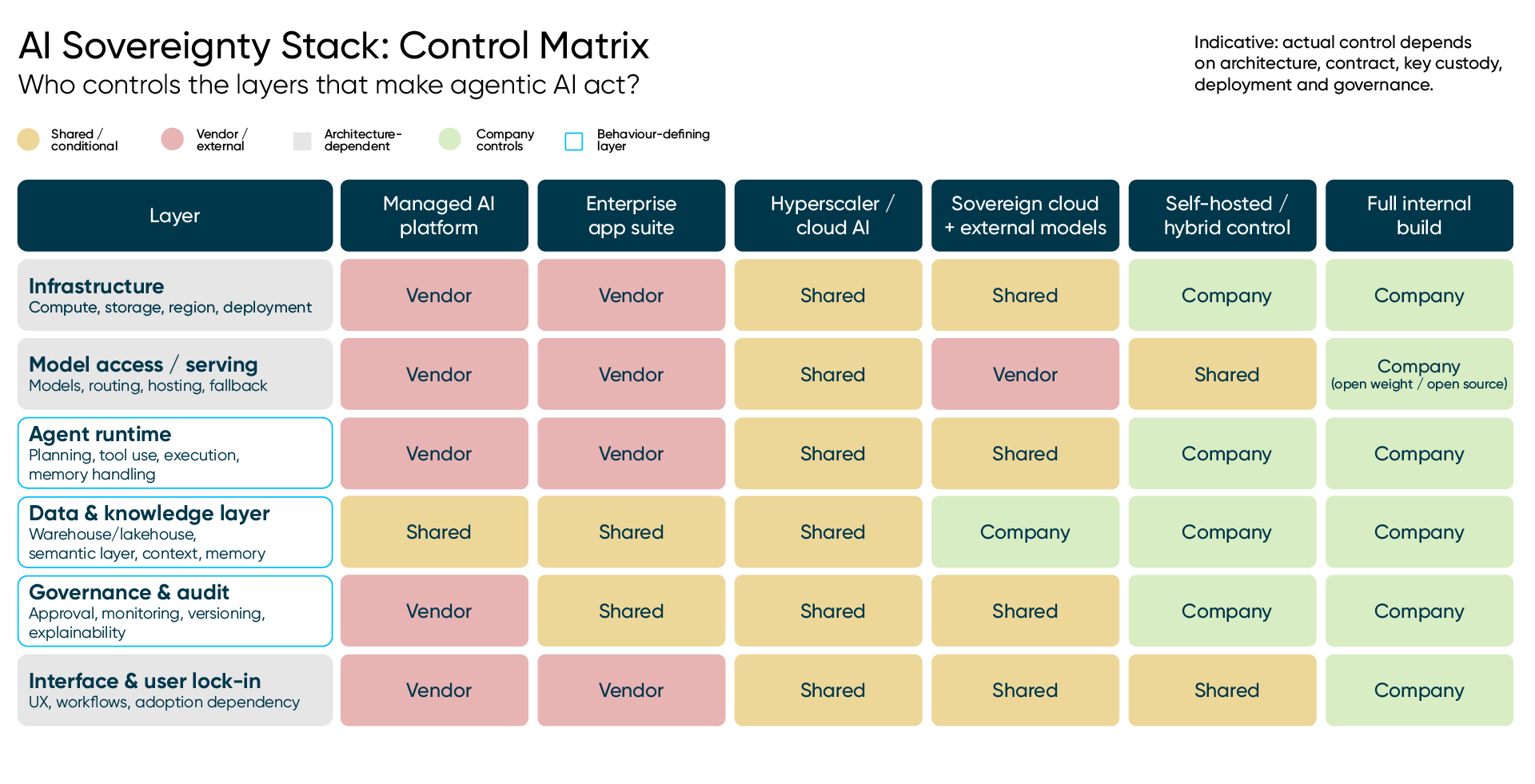
The point of the matrix is not to declare one architecture correct. It is to make visible which one you are actually running and whether the layers you rent are the layers you can afford to rent.
Regulation is moving in the same direction
I would not treat this as a solved field yet. There is no settled standard for how the upper layers of agentic systems should be owned, governed, exported and verified across platforms.
The regulatory side is moving in the same direction.
The EU AI Act is pushing the market toward documentation, auditability and post-market monitoring for high-risk AI systems, while practical enforcement and audit practice are still maturing.
In financial services, the switchability question is already more concrete. Under DORA, firms must manage ICT third-party risk, maintain registers of ICT arrangements, assess concentration risk, and put exit strategies and transition plans in place for ICT services supporting critical or important functions.
That matters for the kind of organisations I work with. Many operate in regulated environments, where being able to inspect, explain and move operating context is the difference between a system they can defend and one they cannot.
This is where my own work sits. We are already building these control layers in different forms, internally and with clients: keeping context, governance and operating memory owned, inspectable and portable rather than trapped in someone else's execution layer.
Not a finished framework. A direction we are building in practice, one layer at a time.
AI needs more than a powerful model
Successful AI is built on reliable data, clear governance and a solid architecture. See where your organization stands today.
Assess your AI foundationFrom technology sovereignty to decision sovereignty
This matters most in analytics, where agents stop observing and start participating.
Classical BI kept a human buffer. A dashboard informed someone, a report supported a meeting, and the judgement happened elsewhere. Agentic analytics collapses that buffer. The system explains changes, identifies anomalies, recommends actions, updates records, opens tickets, drafts narratives and escalates risk.
At that point, weak or vendor-locked context is an operating risk.
A misread metric becomes a wrong recommendation. A wrongly trusted source becomes a wrong escalation. Ungoverned corrections become reproduced bias. The question shifts from infrastructure to decision control.
Can the organisation still change providers? Can it inspect why a recommendation happened? Can it prove which source, rule or definition shaped an answer? Can it stop, override or reroute an automated process? Can it move its operating memory somewhere else?
That is the shift from technology sovereignty to decision sovereignty.
The provenance layer
The same pattern appears in digital provenance, just in another domain.
If origin, rights and context depend entirely on a closed platform, trust becomes platform-dependent. In enterprise AI, if memory, skills and operating context depend entirely on a closed agent platform, intelligence becomes platform-dependent.
Different problem surface, same architectural question: can the proof travel?
Can the context be verified beyond the system that currently displays it? Can the record survive a platform change? Can an institution, a company or a user still understand where something came from, what changed, who approved it and why it should be trusted?
That is why I do not see provenance only as a media-integrity topic. It is part of the broader control infrastructure AI systems will need.
Provenance of content. Provenance of knowledge. Provenance of decisions.
The domains are different, but the underlying requirement is similar: trust should not depend on one closed environment continuing to exist, cooperate or remain accessible.
What this moment actually taught us
AI sovereignty matters. But I would not reduce it to cloud region, provider nationality or model choice. It is not a single tool decision — it is a property of the whole stack.
The model layer just proved it can move. The practical response is to make sure the layers that move are replaceable — and that the layers carrying organisational memory are not trapped with them.
The first generation of enterprise AI adoption asked: which model should we use? The next generation will ask: which layers do we control? More concretely: where does our operational memory live, who can verify it, and can we take it with us?
Models can change. Providers can change. Prices and access can change, sometimes over a single weekend. But the context that makes AI useful inside an organisation should not disappear when one layer of the stack moves.
Companies that understand this will not just rent AI. They will own the intelligence they build.
This is the thread that runs through both things I work on: governed, owned context at inics, and verifiable provenance at puit.is. Content, context, confidence — across the stack.
AI sovereignty starts in the stack
We help you design AI architectures where context, governance and operational knowledge remain under your control.
Schedule an architecture discussionThomas Howert
Co-Founder & Senior Advisor for BI, data projects, and technology decisions
Discover more articles

AI Use Case Inventory and Governance - Portfolio, Roles, Obligations
Part 3/3 concludes the series with the question that, in practice, often needs to be answered first:

From Insight Risk to Action Risk: Why Agentic Analytics Changes What Governance Is For
In classical BI, weak governance was a reporting problem. In agentic analytics, it becomes an execution problem. That single shift changes what governance is for - and where organisations need to start before they scale AI.

The Analytics Agent Already Works in Your Company
The problem is that most of its knowledge is still in someone’s head. In many companies, the closest thing to an analytics agent is still a person. The analyst who knows which dashboard people actually trust. The controller who remembers why one margin definition is dangerous. The BI consultant who has seen the same simple metric mean three different things across three source systems. The data engineer who knows which table exists, and why it should still not be used for the question someone is asking.